Kneser-Ney smoothing
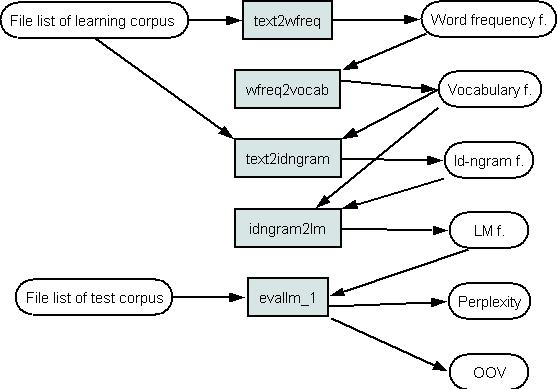
Perplexity and OOV for a model with Kneser-Ney smoothing can be estimated using the kn1. In this case a language model file is not created as in Picture 1. The tool loads language model into computers memory from vocabulary and reversed id-ngram file (See Picture 1 for a vocabulary file, reversed id-ngram file is generated by the idg2rev_idg). The tool kn1 evaluates word probability estimates. The calc_perplexity calculates perplexity and OOV.
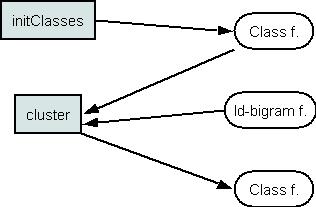
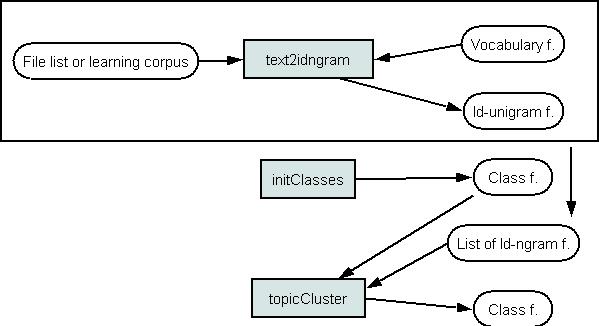
A word to class mapping file can be initialized by the InitClasses. There is a possibility to assign word to classes 1) randomly or 2) all words to one class. The cluster automatically groups words by exchange algorithm using mutual information criterion (the id-bigram file is needed for this). This tool return new word-class map file.
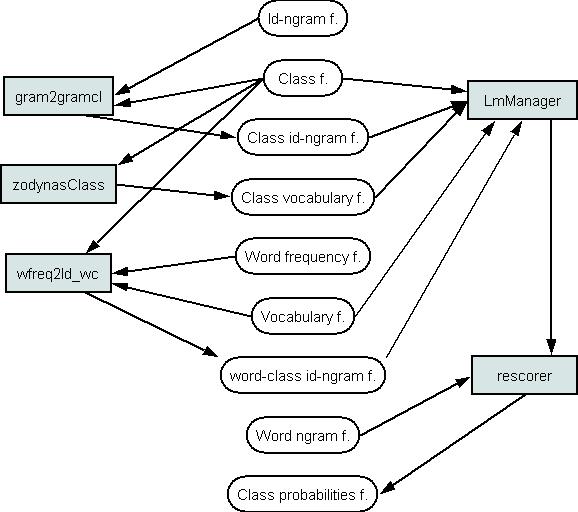
The tools can implement the class-based model P(c|cc)P(w|c). Using these tools the class id-ngram, class vocabulary and class-word id-bigram files are prepared according to class map file. The LMManager prepares and loads the class-based model and the Rescorer calculates word probability estimates. Perplexity can be evaluated with the calc_perplexity. Class-based and word ngram models can be joined by linear interpolation, see here.
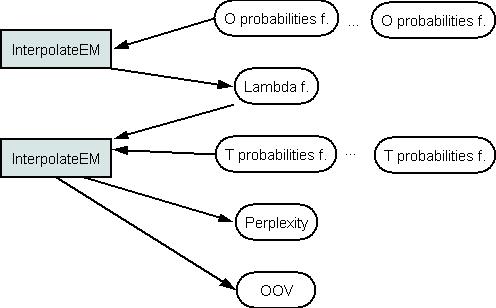
The InterpolateEM is prepared for linear interpolation of models. The model weights lambda can be estimated using probability files of an optimization corpus. The InterpolateEM can also join the test corpus probabilities that are estimated using several language models according lambda weights and calculate perplexity of the compound model.
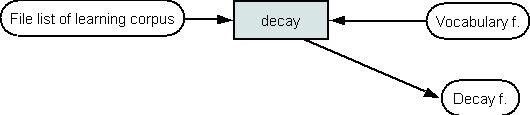
Decay function can be estimated using learning test corpus.
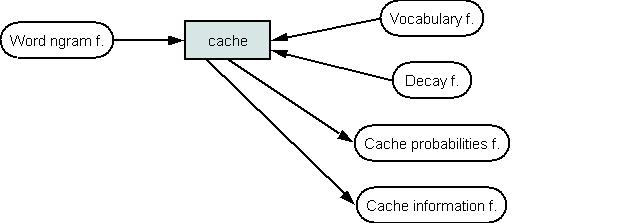
Implementation of cache models is done by the cache. This tool calculates unigram or bigram cache probabilities. The probability files can be joined with ngram probabilities using linear interpolation (See Picture 5). Cache information file is returned for conditional linear interpolation (see description of the intCache).
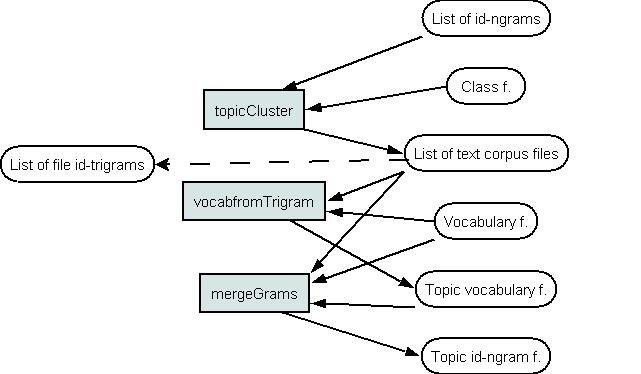
This picture presents a schema for an automatic text file clustering to topics. The id-unigram files should be prepared for every text file. These id-unigram files are used for clustering. Text-class map file is analogous to word-class map file. The topicCluster does the clustering and returns the new text-class map file.
The tools vocabFromTrigram and mergeGrams prepare vocabulary and id-ngram files for every topic. These tools use the idtrigram files of every text file (should be prepared before by the text2idngram). The probabilities using different topics can be estimated in the same way as noted in Picture 2. The model probabilities can be joined using the interpolateEM.
The id-bigram files for skip bigram models can be prepared by the text2idngram_s. The probability estimation can be done as noted in Picture 2. Test word ngram sequences for probability estimation can be prepared by the skaldymas_class. For a linear interpolation of skip bigram models see Picture 5.
The toolkit includes the tools for the creation of the morphology-based models. The following types of morphology-based models are implemented:
P(s|ss)P(g|ggs) and P(s|ss)(a P(g|s) + (1-a) P(g|gg)), where "s" is a word beginning and "g" is a word ending.
Word beginning trigram "sss" and word ending 4-gram "ggsg" data files can be calculated by the idg2ids_idgs with the input of the word id-trigram. The word ending id-trigram can be prepared by the idg2ids_idg, data for the model P(g|s) - by the wfreq2idsg. Language models are created and word probabilities can be evaluated by the kn1. The word ngram for probability evaluation of test corpus can be prepared before by the skaldymas.

Word clustering
Building class-based models
Realization of linear interpolation
Estimation of decay function (for cache models)
Building cache models
Clustering of text files
Building topic mixture models
Building skip bigrams
Building morphology-based models
Use of language model from other applications
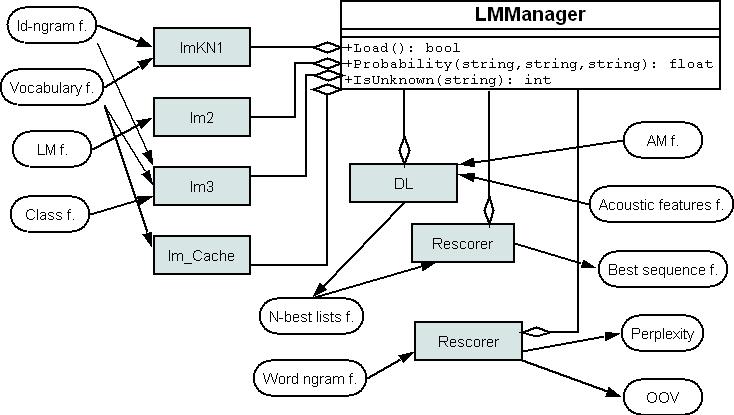
For this purpose the tool lmManager is created. This tool load a language model into computers memory. Other applications can join to the lmManager using COM interface and get the probability estimation of any word sequence. Examples of these applications are: the rescorer calculates perplexity or rescores N-best list, the dl is a large vocabulary continuous speech decoder. Complete list of provided COM functions of the lmManager can be found here (there is also provided an example of using the lmManager from C++ code).